
Los modelos de lenguaje masivos, como el entrenamiento de un LLM, requieren aproximadamente 1 billón de palabras, lo que equivale a unos 30.000 años de escritura.
¿Alguna vez te has preguntado de dónde proviene esta inmensa cantidad de datos? Es decir, ¿De dónde extraen datos los grandes modelos de lenguaje?
En este artículo, exploraremos los conjuntos de datos de texto (Text datasets) utilizadas por modelos de lenguaje como OpenAI y cómo se relaciona con las protestas en Reddit.
Navegando por el océano de información: CommonCrawl
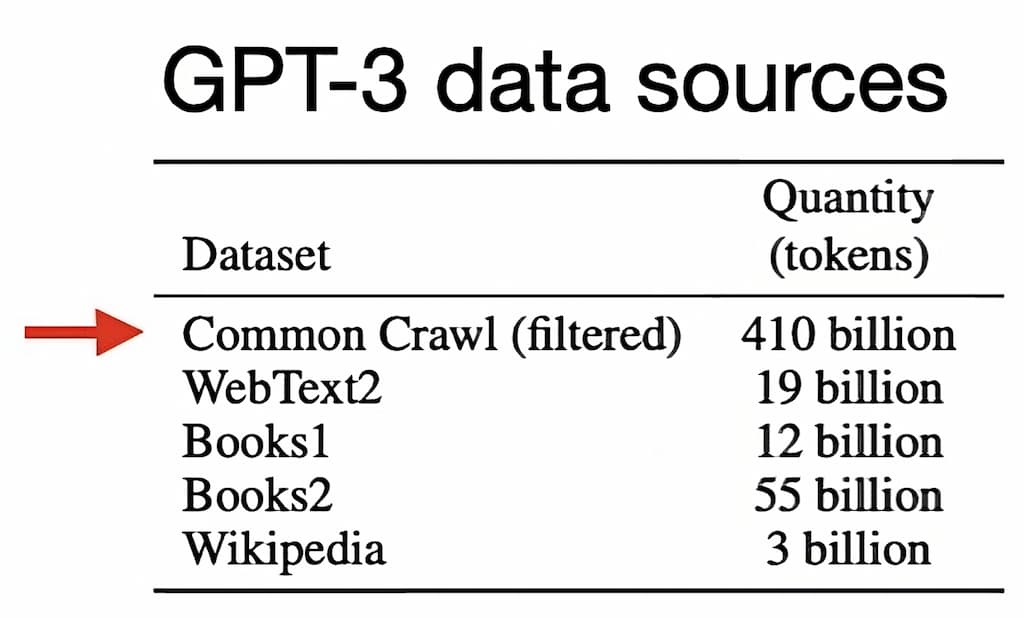
Tabla con datos en inglés 1 billion = mil millones
Cuando escuchamos que los LLM están entrenados en «todo el internet», esto proviene del uso de CommonCrawl. CommonCrawl es una organización sin fines de lucro que rastrea la web con bots y registra todo lo que encuentra desde 2008. Sin embargo, el 90% del contenido es HTML, CSS y scripts, dejando solo el 10% restante como datos útiles. Pero incluso esa parte contiene basura que debe ser eliminada.
Limpieza de datos: la búsqueda del tesoro escondido,
¿Por qué Reddit es la mina de oro para los modelos de lenguaje?
OpenAI creó el conjunto de datos WebText extrayendo enlaces de publicaciones en Reddit que recibieron más de 3 votos positivos. Estos enlaces suelen contener artículos de noticias y publicaciones de blogs de alta calidad. Además, OpenAI ha utilizado Reddit para entrenar modelos anteriores, como los resúmenes TL;DR. La dependencia de OpenAI de Reddit ha llevado a la plataforma a cobrar por los datos, generando protestas entre los usuarios.
Otros tesoros de información: Wikipedia, ArXiv y más
![]()
Además de CommonCrawl y Reddit, muchos modelos utilizan fuentes como Wikipedia y ArXiv. Estas plataformas liberan volúmenes periódicos de datos para desincentivar el rastreo. Aunque parezcan enormes, cada una de estas fuentes representa menos del 1% de un CommonCrawl limpio.
El enigma de los «libros» de OpenAI
Uno de los aspectos más misteriosos de OpenAI son sus «libros». Existen leyendas sobre si Books2 proviene del servidor (¿ilegal?) LibGen o si Books1 tiene su origen en Smashwords/Project Gutenberg. La verdad sigue siendo un misterio, como si hubieran sido escritos por gnomos.
![]()
Conclusión: saciando la sed de palabras
En resumen, los modelos de lenguaje masivos obtienen sus datos de una combinación de CommonCrawl, Reddit, Wikipedia, ArXiv y otros recursos enigmáticos. Al igual que un cazador de tesoros que busca joyas ocultas en el fondo del océano, estos modelos navegan por el vasto mar de información de internet para saciar su sed insaciable de palabras y, en última instancia, mejorar nuestra comprensión del lenguaje humano.



Comentarios